
Most of the CPU time spent in the premultiplier algorithm can be classified into four parts: find_in_arc, find_out_arc, update_tree, and update_pi. In order to analyze which procedure dominates the computation, we record the CPU time spent on different procedures, and divide by the total CPU time. Since the proportion distribution does not vary very much for different network families, we choose the GRIDGEN-WIDE family for our discussion.
For PNS, most of the CPU time is spent in find_in_arc. When the networks become larger, it will spent more time in find_in_arc. (refer to Table5.1) This is predictable from the nonscaling premultiplier algorithm. Therefore, find_in_arc is the bottleneck for the nonscaling premultiplier algorithm.
For PS1, more CPU time is spent in update_pi than find_in_arc. For larger networks, update_pi is still the dominant procedure. (see Table 5.2) We did not foresee that the update_pi procedure would take so much time for the algorithm. Obviously, there are too many iterations of update_pi which use D2 but do not find any entering arc. This is very unprofitable, and wastes too much time. Therefore, speeding up the update_pi procedure for the scaling premultiplier algorithm is very important.
For PS2, we intended to avoid those unprofitable iterations of update_pi in PS1, but it came with the price of scanning many arcs in update_pi. For smaller networks, there are fewer iterations of find_in_arc, and thus the scanning arcs in update_pi becomes dominant. For larger networks, although we still spend much time in update_pi, we need more time in find_in_arc. (see Table 5.3)
------------------------------------------------------------------------------
# | PNS
|-----------------------------------------------------------------------
nodes | find_in_arc | find_out_arc | update_tree | update_pi | Total CPU time(s)
==============================================================================
512 | 92.39% 2.09% 1.51% 1.90% | 4.41
1024 | 93.75% 1.99% 1.38% 1.57% | 15.55
2048 | 94.76% 1.69% 1.25% 1.46% | 53.47
4096 | 95.61% 1.44% 1.16% 1.31% | 204.55
8192 | 95.87% 1.30% 1.20% 1.32% | 727.51
16384 | 95.90% 1.15% 1.39% 1.35% | 2381.14
------------------------------------------------------------------------------
# | PS1
|-----------------------------------------------------------------------
nodes | find_in_arc | find_out_arc | update_tree | update_pi | Total CPU time(s)
==============================================================================
512 | 22.07% 0.73% 0.60% 72.08% | 12.13
1024 | 19.82% 0.70% 0.52% 75.63% | 36.91
2048 | 16.17% 0.62% 0.46% 80.62% | 129.47
4096 | 14.62% 0.56% 0.46% 82.91% | 419.23
8192 | 14.17% 0.48% 0.48% 83.94% | 1456.30
16384 | 16.85% 0.44% 0.57% 81.51% | 4621.69
------------------------------------------------------------------------------
# | PS2
|-----------------------------------------------------------------------
nodes | find_in_arc | find_out_arc | update_tree | update_pi | Total CPU time(s)
==============================================================================
512 | 36.64% 2.22% 1.63% 53.52% | 4.67
1024 | 38.82% 2.46% 1.72% 52.06% | 12.60
2048 | 42.91% 2.51% 1.85% 48.92% | 34.57
4096 | 48.14% 2.58% 2.06% 82.91% | 99.85
8192 | 54.47% 2.27% 2.21% 39.13% | 326.41
16384 | 60.41% 1.81% 2.32% 34.40% | 1184.17
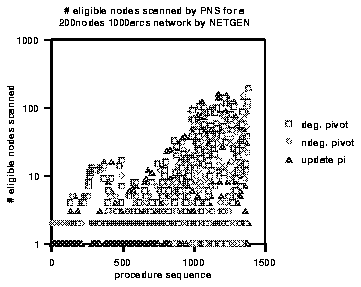
The premultiplier algorithm avoids maintaining simplex multipliers at each stage. However, we found that this algorithm will slow down near the end because it scans more and more nodes. Figure 5.1 illustrates an example of the history of scanning nodes for procedures find_in_arc and update_pi. The squares in the Figure represent the number of eligible nodes scanned in a degenerate pivot; circles represent the number of eligible nodes scanned in a nondegenerate pivot; and triangles represent the number of eligible nodes scanned so that we have to modify the premultipliers. In this example using the nonscaling algorithm has 400 degenerate pivots, 408 nondegenerate pivots6 and 574 iterations of update_pi. From Figure 5.1, we see the number of nodes scanned grows near the end of the computation.
Since the premultiplier algorithm must start from the root, and the root may change in later iterations, when the number of eligible nodes grows, it will slow down. Unlike the original network in which we could starting searching for the entering arc from any node. We have already applied the concept of CurrentArc(i) to avoid scanning many arcs; however, it is not good enough.
There is another point which may slow down this algorithm: because we are maintaining premultipliers, we may not identify an admissible arc by only scanning one of its end nods. For example, if we find (i,j) is not admissible when we scan node i, we may find (j,i)7 is admissible in the same iteration of find_in_arc if later we find j is eligible. That is, we may need to scan an arc twice to make sure it's not admissible, which will waste some time. This differs with the original network simplex algorithm in which we can identify an entering arc by scanning either one of its end nodes.
For the generic scaling premultiplier algorithm, our implementation of update_pi performs poorly despite its good theoretical running time. Generally speaking, we should try to decrease the time spent in update_pi, and let the algorithm perform pivots as often as possible. Our implementation of the generic scaling premultiplier algorithm spends too much time in update_pi. We have made the second scaling premultiplier algorithm spend less time in update_pi; however, it scans all the adjacent arcs for all the eligible nodes in its update_pi procedure. This slows down the algorithm. To speed up the scaling premultiplier algorithm, we should find better ways to avoid spending too much time in update_pi.
The idea of switching two modes and methods in the procedure find_in_arc of scaling premultiplier algorithm did save much time. From our experience, there are always very few reawakened nodes after we updated D2 . This will speed up more for larger networks because we can skip scanning many eligible nodes which are asleep.
By comparing the results of our premultiplier codes with OLD, the original network simplex code, we found that all the premultiplier codes have much fewer iterations of pivots than OLD. On the other hand, this might suggest that we spend too much time in each pivot in the premultiplier algorithm. We are unable to analyze CS2 to get its number of pivots for comparison.
We did not use the concept of strong feasibility here in this thesis. We could have done so using a perturbation approach. We would not have used the usual implementation of strong feasibility since it preserves that a root node is held fixed, whereas the root in premultiplier algorithm varies from pivot to pivot.
All the three codes developed for this thesis follow the original ideas in Orlin's paper [2]. So far, their performance is not comparable to the mature code CS2. Note that the CS2 code we use in this thesis was modified from its original version used in Goldberg's paper [4]. According to Goldberg, this modified code is 10%-90% faster than its original version [8]. Based on our tests and on Goldberg's tests, we anticipate for larger networks our scaling codes are better than NETFLO, another widely used network simplex code by Kennington and Helgason [9]. We also anticipate that our modified scaling code PS2 performs similarly to the simplex code RNET by Grigoriadis [10].
The key .52% 75.63% | 36.91 2048 | 16.17% 0.62% 0.46% 80.62% | 129.47 4096 | 14.62% 0.56% 0.46% 82.91% | 419.23 8192 | 14.17% 0.48% 0.48% 83.94% | 1456.30 16384 | 16.85% 0.44% 0.57% 81.51% | 4621.69
-------------------------------------------------------------------2 runs faster and is more stable. We conclude that it is the best of premultiplier codes tested in this thesis.
6.When the network becomes larger, most of the pivots will become degenerate.
7.Here we mean (i,j) and (j,i) correspond to the same arc in the original network.
Previous: Return Chapter 4
Next: Go to Appendix
Go to Premultiplier C Codes